
The Missing Levels of AI-Assisted Development: From Agent Chaos to Orchestration
Introduction
A few months ago I wrote about shifting from AI implementer to AI orchestrator and, shortly after, about the AI coding agent dashboard I built to keep that orchestration from collapsing under its own weight. The response surprised me. The most common question was not "how do I get started?" but "how do I get past this?".
Most developers I talk to can picture the first few steps up the AI-assisted development ladder. Turn on autocomplete, let the agent edit files, trust it a little more every week. What nobody seems to agree on is what happens once you have five, ten, or twenty agents running, and it has stopped feeling like productivity and started feeling like a second full-time job.
Steve Yegge has a useful framework for this. His 8 levels of AI-assisted development, as described on The Pragmatic Engineer, have become a common shorthand among people thinking seriously about coding agents. The more I sit with it, the more I suspect Level 7 and Level 8 are not one step apart. They are four or five. This post is not a finished map. It is my current sense of the rungs that seem to be there, based on my own climb so far.
Steve Yegge's 8 Levels of AI-Assisted Development
Steve Yegge's 8 levels of AI-assisted development describe a developer's progression from no AI assistance to building a custom agent orchestrator. As described in his Pragmatic Engineer interview:
- Level 1: No AI.
- Level 2: IDE coding agent with permissions on.
- Level 3: IDE coding agent in YOLO mode.
- Level 4: Conversation over diff review.
- Level 5: CLI-first workflow; the IDE is no longer home.
- Level 6: Several parallel agents.
- Level 7: Ten-plus agents, coordinated by hand.
- Level 8: A custom agent orchestrator.
Levels 1 through 5 are mostly about trust in one agent. Level 6 is where parallelism starts to pay off. Level 7 is the moment you realize you are not ready for parallelism. Level 8 is the moment you decide to build your way out of the mess.
That is a good ladder. It also has a very large missing rung.
The Gap Between Level 7 and Level 8
Read Yegge's own description of the leap and something jumps out: there is no middle. One paragraph you are texting the wrong agent by accident and misplacing work in tmux windows; the next paragraph you are writing an orchestrator in Go. Addy Osmani captures the same transition in his "Code Agent Orchestra" piece with one of my favorite lines of the year:
The bottleneck is no longer generation. It's verification.
That is exactly what breaks at Level 7. You can produce more code than you can realistically review. Specs silently drift between agents because each one is working from the prompt you gave it, not a shared source of truth. Two agents edit overlapping files and neither knows. You rubber-stamp pull requests that you would have rejected at Level 5. And the cognitive cost of twelve parallel threads starts to erase the productivity you went looking for.
Jumping from there to "build your own orchestrator" is, for almost everyone, unrealistic. Writing a task scheduler is not the hard part. The hard part is figuring out what to schedule, when a human should intervene, and how to retain enough understanding of the system to stay the person in charge of it.
Those are not engineering problems. They are workflow problems. And they have rungs of their own.
The Missing Levels Between Agent Chaos and Orchestration
What follows is my current sense of the sequence between Yegge's Level 7 and Level 8. I have climbed some of these rungs. Others I can only see from below. Think of them as an agentic Software Development Lifecycle (SDLC) maturity model for the mid-game, where agent autonomy goes up but your visibility into the system has to go up with it.
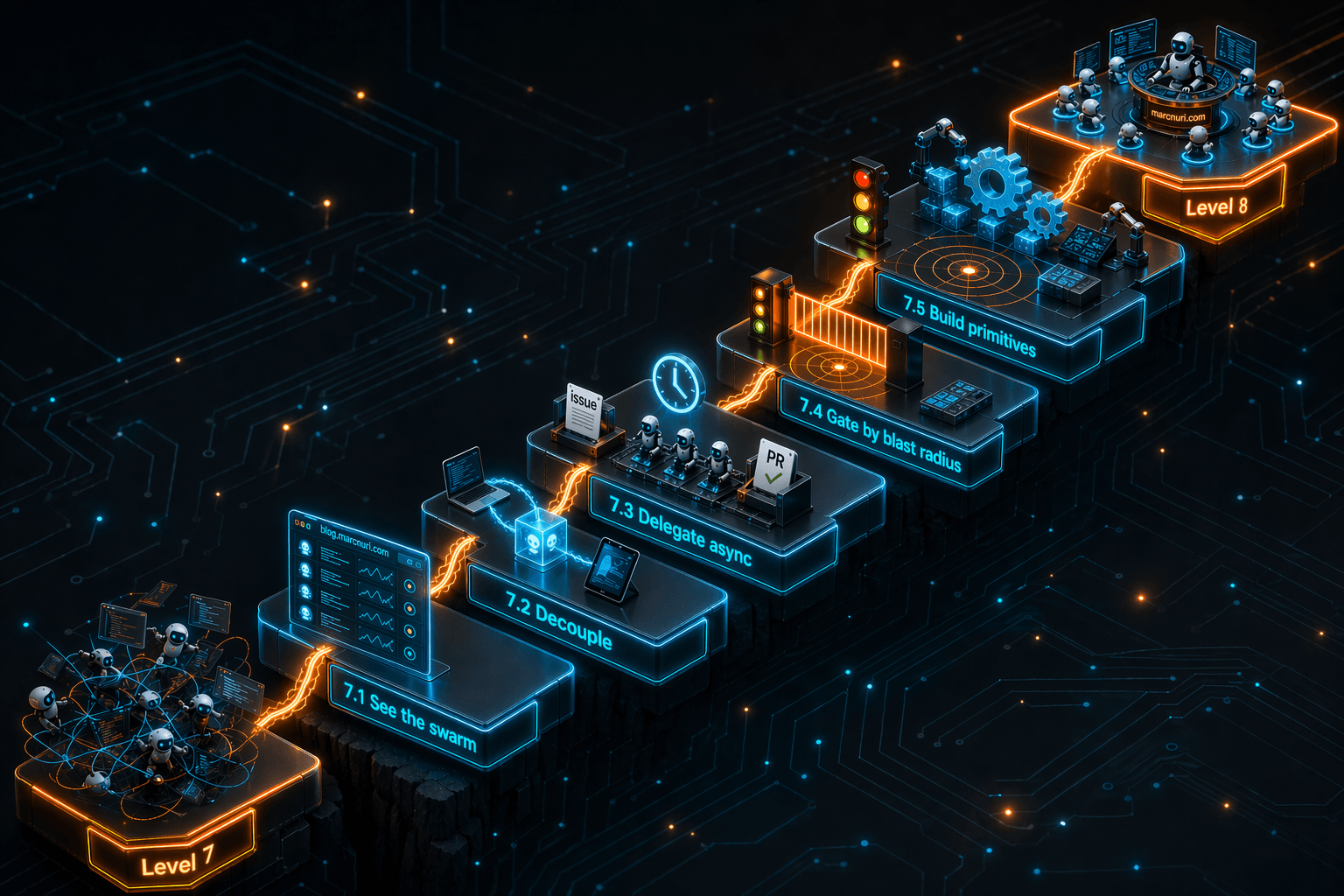
7.1 — See the swarm
The first thing that breaks at Level 7 is not the agents. It is your memory of them.
You cannot coordinate what you cannot see, and at ten-plus concurrent sessions, tmux tabs and terminal windows stop being a mental model. You start forgetting which coding agent is doing what, which branch it is on, which one is stalled waiting for permission, and which one finished an hour ago. What fixed this for me was not a new agent or a better model. It was externalizing the state of every session into one view I could glance at.
That is what the coding agent dashboard I built earlier this year does. It pulls the device, branch, model, context usage, status, and current task of every active session into one place. You do not need my dashboard for this rung. You need a dashboard. A spreadsheet, a shell script, anything that externalizes what your working memory can no longer hold.

7.2 — Decouple from the machine
Once you can see all your agents, the next thing you want is to stop being chained to the machine they run on.
My daily setup involves a laptop and a Linux workstation. Before this rung, agents were pinned to whichever machine I happened to start them on. After it, I could spawn a session on the workstation from my laptop, attach to a session on the workstation from my phone, and kick off work from a tablet on the couch. I did not want to work more hours. I wanted to stop paying the friction of "is this the machine the agent is on?" every time I switched contexts.
There is more than one way up this rung. A shared tmux server reachable over SSH gets you part of the way. Tools like tmate, Tailscale, or any browser-accessible terminal close the gap further. What matters is that the agent stops being pinned to a physical device and starts being reachable from wherever you happen to be.
This is where parallelism stops being a local trick and starts becoming a property of your workflow. Cross-device visibility and control turn a group of parallel agents into something closer to a multi-agent team that happens to share your laptop.

7.3 — Delegate asynchronously
Up to here, every agent is still waiting for you. You start it, you watch it, you answer its questions.
The next rung is letting go of that loop. GitHub Copilot coding agent workflows, and similar issue-to-pull-request agent workflows, change the unit of work from "a terminal session" to "a well-written issue and a pull request". You describe the change in prose, assign it, walk away, and review the result whenever you get to it. Long-running tasks progress while you are on a call, on a train, or asleep.
This is the rung where the quality of your project starts to dominate the quality of your output. Async delegation only works if the agent has enough context to succeed without you in the room: clear specs, strong test coverage, and well-scoped interfaces. A well-structured codebase amplifies the agent. A chaotic one amplifies the chaos.

7.4 — Gate by blast radius
This is the rung I have not climbed yet.
At Level 7 I have more work flowing through more agents than I can possibly inspect line by line, and I still try to. I review every pull request. I open every diff. It is exhausting, and I know it does not scale, but the alternative feels reckless.
I think the better move is to decide in advance which decisions deserve a human gate, instead of compensating for the volume with fear. Not "does this need approval?", because the honest answer is always "probably". The more useful question is why it would need approval:
- How big is the blast radius: one component, or a dozen services?
- Is the change reversible in minutes, or would rolling it back take hours?
- Does it commit the project to anything external, such as money, contracts, or third-party accounts?
- Is it visible to users, customers, or stakeholders if it goes wrong?
If all four are low, the agent could in theory proceed on its own and tell me after the fact. If any one of them is high, the agent stops and waits for me. This is not a new idea. Incident response teams have lived on similar dimensions for years. The hard part is encoding it into a workflow so it actually shapes what lands on my review queue, instead of just being a diagram on a slide.
A fifth, boring dimension deserves a mention here: cost. Ten agents running continuously against a capable model is not free, and the bill grows quietly while you sleep. Treating spend as just another gate, with per-session budgets and a hard ceiling, is the difference between an experiment and a surprise.
If I get this rung right, human time moves from tasks to decisions, which is where it actually belongs. I am not there yet. Most of the time I am still staring at diffs.
7.5 — Build the primitives
The last rung before a real orchestrator is where things stop being policies and start being code.
At some point the dashboard needs to know more than where your sessions are. It needs to know which tasks are queued and which are in flight, so two agents do not grab the same issue. The smallest version I have been sketching in my head is a shared list of open issues, a lightweight "claimed" flag, and an agent-side hook that checks before picking one up. Barely a hundred lines of glue, and yet it seems like it would be the single biggest reduction in duplicated work I can imagine.
From there the primitives accumulate quickly. Checkpointing long-running sessions so a crash does not lose an afternoon of work. Scoped, short-lived credentials per session so "the agent has my credentials" stops being a sentence that keeps you up at night. A way to feed spec updates back to an agent that was started twenty minutes ago.
None of that is a custom orchestrator yet. But each of those primitives is what a custom orchestrator would be made of. If they accumulate one at a time, Level 8 stops being a weekend project and becomes the natural conclusion of a pile of small, pragmatic tools. This is the direction my tooling keeps pulling me in, even when I am not actively building for it.
Beyond Level 8: Fully Autonomous Software Development
Yegge's Level 8 is "build your own orchestrator", but it is not the end of the road. Dan Shapiro's five levels from spicy autocomplete to the Dark Factory describe a very different endpoint: Level 5, the Dark Factory. A software process that takes specifications in and ships software out, with no human writing or reviewing code.
It is no longer hypothetical. Simon Willison has documented how StrongDM's three-person team has been operating this way since mid-2025, shipping a codebase of around 32,000 lines of Rust, Go, and TypeScript under a rule that no human writes or reviews the code. The questions it raises, about specification quality, the information barrier between builder and evaluator, and who is accountable for a codebase nobody has read, deserve a post of their own.
For now I am comfortable saying I am not there, and I am not sure I want to be. The climb I am describing stops well short of that.
Conclusion
Frameworks like Yegge's are useful because they let us talk about where we are and where we are trying to go. But a ladder with a missing rung is not a ladder. It is a drop. And the drop between "ten agents managed by hand" and "build your own orchestrator" has swallowed a lot of promising AI-assisted workflows.
The climb between them is not glamorous. It is visibility, distribution, asynchrony, gating, and small primitives. Five quiet rungs that together make Level 8 feasible and, much more importantly, make Level 7 survivable.
There is also a second question hiding beneath the whole climb: not how high you go, but what the tools you are climbing with are built around — the project, the agent, or you. It is a large part of why the orchestrator ends up being yours to build.
If you are somewhere on this climb, I would like to hear where. I am tracking feedback and ideas on the ai-beacon discussions while I work on the tooling, so that is the best place to compare notes. The more of them we share, the better the next version of the ladder will be.




