
Los Niveles que Faltan en Desarrollo Asistido por IA: Del Caos a la Orquestación
Introducción
Hace unos meses escribí sobre cómo pasé de implementador de IA a orquestador de IA y, poco después, sobre el dashboard de agentes de codificación que construí para que esa orquestación no se derrumbara bajo su propio peso. La respuesta me sorprendió. La pregunta más común no fue "¿cómo empiezo?" sino "¿cómo paso de aquí?".
La mayoría de desarrolladores con los que hablo pueden imaginar los primeros pasos en la escala del desarrollo asistido por IA. Activa el autocompletado, deja que el agente edite archivos, confía un poco más en él cada semana. En lo que nadie parece ponerse de acuerdo es en qué pasa una vez que tienes cinco, diez o veinte agentes corriendo, y ha dejado de sentirse como productividad para empezar a sentirse como un segundo trabajo a tiempo completo.
Steve Yegge tiene un marco útil para esto. Sus 8 niveles de desarrollo asistido por IA, descritos en The Pragmatic Engineer, se han convertido en vocabulario común entre quienes piensan seriamente sobre agentes de codificación. Cuanto más lo analizo, más sospecho que el Nivel 7 y el Nivel 8 no están a un solo paso de distancia. Están a cuatro o cinco. Este artículo no es un mapa cerrado. Es mi percepción actual de los peldaños que parecen estar ahí, basada en mi propia experiencia hasta ahora.
Los 8 Niveles de Desarrollo Asistido por IA de Steve Yegge
Los 8 niveles de desarrollo asistido por IA de Steve Yegge describen la progresión de un desarrollador desde la ausencia de IA hasta la construcción de un orquestador de agentes personalizado. Tal y como se describen en su entrevista en Pragmatic Engineer:
- Nivel 1: Sin IA.
- Nivel 2: Agente de codificación en el IDE con permisos activos.
- Nivel 3: Agente de codificación en el IDE en modo YOLO.
- Nivel 4: Conversación en vez de revisión de diffs.
- Nivel 5: Flujo de trabajo CLI-first; el IDE deja de ser el hogar.
- Nivel 6: Varios agentes en paralelo.
- Nivel 7: Diez o más agentes, coordinados a mano.
- Nivel 8: Un orquestador de agentes personalizado.
Los niveles 1 al 5 van principalmente sobre la confianza en un único agente. El Nivel 6 es donde el paralelismo empieza a dar frutos. El Nivel 7 es el momento en el que te das cuenta de que no estás preparado para el paralelismo. El Nivel 8 es el momento en el que decides construir tu propia salida del caos.
Es una buena escala. También tiene un peldaño enorme que falta.
El Salto Entre el Nivel 7 y el Nivel 8
Lee la descripción que hace Yegge del salto y algo te llamará la atención: no hay intermedio. En un párrafo estás escribiéndole al agente equivocado por accidente y perdiendo trabajo entre ventanas de tmux; en el siguiente estás escribiendo un orquestador en Go. Addy Osmani captura la misma transición en su artículo "Code Agent Orchestra" con una de mis frases favoritas del año:
El cuello de botella ya no es la generación. Es la verificación.
Eso es exactamente lo que se rompe en el Nivel 7. Puedes producir más código del que puedes revisar de forma realista. Las especificaciones se desvían silenciosamente entre agentes porque cada uno trabaja sobre el prompt que tú le diste, no sobre una fuente de verdad compartida. Dos agentes editan archivos que se solapan y ninguno lo sabe. Aceptas a ciegas pull requests que habrías rechazado en el Nivel 5. Y el coste cognitivo de doce hilos en paralelo empieza a borrar la productividad que fuiste a buscar.
Saltar de ahí a "construye tu propio orquestador" es, para casi todo el mundo, poco realista. Escribir un planificador de tareas no es la parte difícil. La parte difícil es averiguar qué planificar, cuándo debe intervenir un humano, y cómo mantener suficiente comprensión del sistema para seguir siendo la persona que está al mando.
Esos no son problemas de ingeniería. Son problemas de flujo de trabajo. Y tienen peldaños propios.
Los Niveles que Faltan Entre el Caos de Agentes y la Orquestación
Lo que sigue es mi percepción actual de la secuencia entre el Nivel 7 y el Nivel 8 de Yegge. He subido algunos de estos peldaños. Otros solo los veo desde abajo. Piénsalos como un modelo de madurez del Software Development Lifecycle (SDLC) agéntico para la fase intermedia, donde la autonomía del agente aumenta pero tu visibilidad sobre el sistema tiene que aumentar con ella.
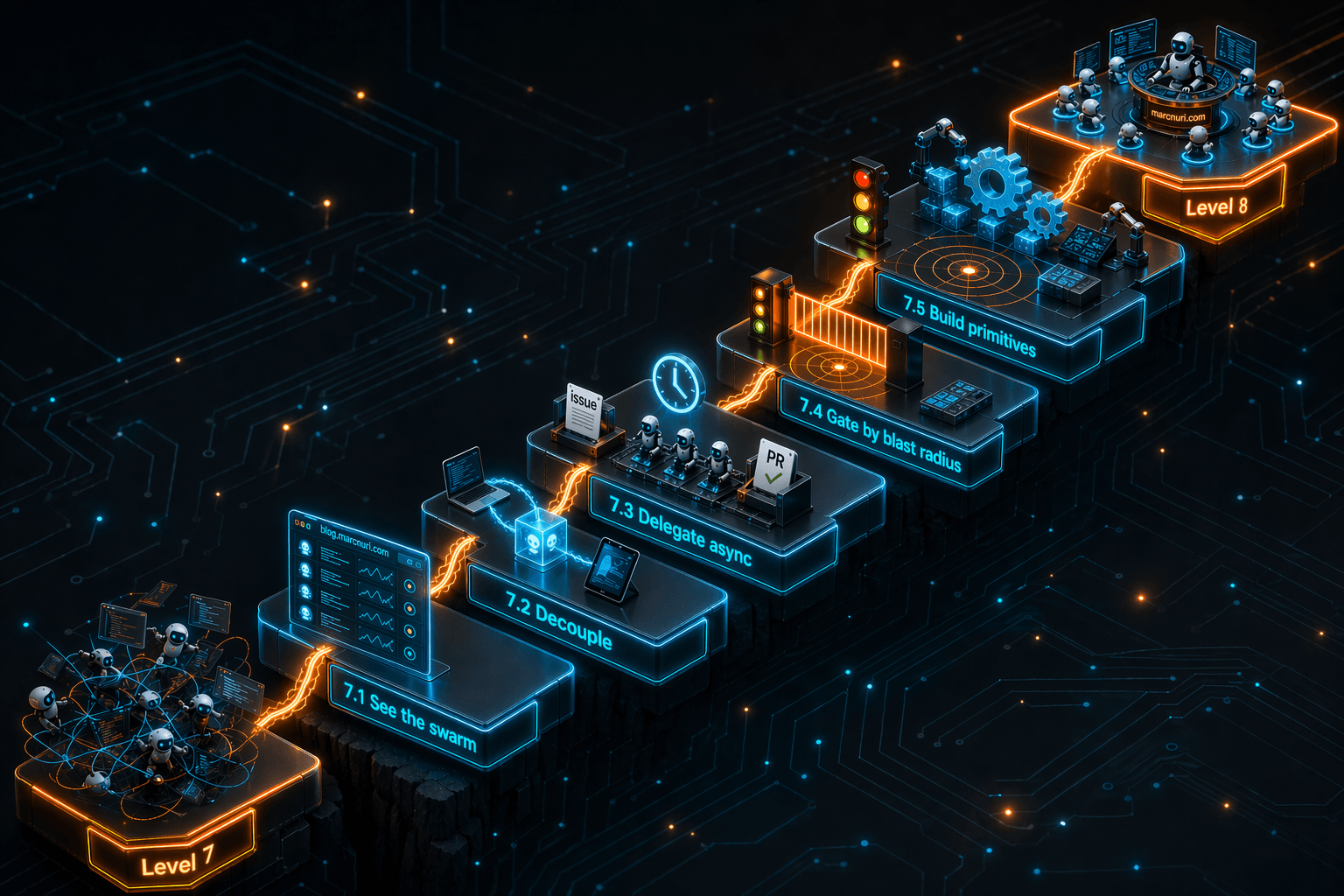
7.1 — Ver el enjambre
Lo primero que se rompe en el Nivel 7 no son los agentes. Es tu memoria de ellos.
No puedes coordinar lo que no puedes ver, y con diez o más sesiones concurrentes, las pestañas de tmux y las ventanas de terminal dejan de ser un modelo mental. Empiezas a olvidar qué agente está haciendo qué, en qué rama está, cuál está detenido esperando permiso, y cuál terminó hace una hora. Lo que me resolvió esto no fue un nuevo agente ni un mejor modelo. Fue externalizar el estado de cada sesión en una única vista a la que pudiese echar un vistazo.
Eso es lo que hace el dashboard de agentes de codificación que construí a principios de este año. Reúne el dispositivo, la rama, el modelo, el uso de contexto, el estado y la tarea actual de cada sesión activa en un solo lugar. No necesitas mi dashboard para este peldaño. Necesitas un dashboard. Una hoja de cálculo, un shell script, cualquier cosa que externalice lo que tu memoria de trabajo ya no puede sostener.

7.2 — Desacoplarte de la máquina
Una vez que puedes ver todos tus agentes, lo siguiente que quieres es dejar de estar encadenado a la máquina en la que corren.
Mi configuración diaria incluye un portátil y una estación de trabajo Linux. Antes de este peldaño, los agentes estaban atados a la máquina en la que los hubiera arrancado. Después, podía lanzar una sesión en la estación de trabajo desde el portátil, conectarme a una sesión de la estación de trabajo desde el móvil, y lanzar trabajo desde una tablet en el sofá. No quería trabajar más horas. Quería dejar de pagar la fricción de "¿es esta la máquina en la que está el agente?" cada vez que cambiaba de contexto.
Hay más de una forma de subir este peldaño. Un servidor de tmux compartido accesible por SSH te lleva parte del camino. Herramientas como tmate, Tailscale, o cualquier terminal accesible desde el navegador cierran el resto. Lo que importa es que el agente deje de estar atado a un dispositivo físico y pase a ser accesible desde donde te encuentres.
Aquí es donde el paralelismo deja de ser un truco local y empieza a ser una propiedad de tu flujo de trabajo. La visibilidad y el control entre dispositivos convierten a un grupo de agentes paralelos en algo más parecido a un equipo multi-agente que casualmente comparte tu portátil.

7.3 — Delegar de forma asíncrona
Hasta aquí, todos los agentes siguen esperándote a ti. Tú los arrancas, tú los observas, tú respondes a sus preguntas.
El siguiente peldaño es soltar ese bucle. Los flujos de trabajo del GitHub Copilot coding agent, y los flujos de agentes de issue a pull request similares, cambian la unidad de trabajo de "una sesión de terminal" a "un issue bien escrito y un pull request". Describes el cambio en prosa, lo asignas, te vas, y revisas el resultado cuando puedas. Las tareas de larga duración avanzan mientras estás en una llamada, en un tren, o durmiendo.
Este es el peldaño en el que la calidad de tu proyecto empieza a dominar la calidad de tu resultado. La delegación asíncrona solo funciona si el agente tiene contexto suficiente para tener éxito sin ti en la sala: especificaciones claras, buena cobertura de tests, e interfaces bien delimitadas. Un codebase bien estructurado amplifica al agente. Uno caótico amplifica el caos.

7.4 — Controlar por radio de impacto
Este es el peldaño que todavía no he subido.
En el Nivel 7 tengo más trabajo pasando por más agentes del que puedo inspeccionar línea a línea, y aun así lo intento. Reviso cada pull request. Abro cada diff. Es agotador, y sé que no escala, pero la alternativa me parece imprudente.
Creo que el movimiento correcto es decidir por adelantado qué decisiones merecen un control humano, en lugar de compensar el volumen con miedo. No "¿esto necesita aprobación?", porque la respuesta honesta siempre es "probablemente". La pregunta más útil es por qué necesitaría aprobación:
- ¿Cómo de grande es el radio de impacto: un componente, o una docena de servicios?
- ¿El cambio es reversible en minutos, o revertirlo llevaría horas?
- ¿Compromete al proyecto con algo externo, como dinero, contratos, o cuentas en terceros?
- ¿Es visible para usuarios, clientes o stakeholders si algo sale mal?
Si las cuatro son bajas, el agente podría en teoría proceder por su cuenta y avisarme después. Si cualquiera es alta, el agente se detiene y espera por mí. No es una idea nueva. Los equipos de respuesta a incidentes llevan años viviendo sobre dimensiones parecidas. La parte difícil es codificarlo en un flujo de trabajo para que realmente moldee lo que llega a mi cola de revisión, en lugar de quedarse en un diagrama de una diapositiva.
Una quinta dimensión, aburrida, merece mención aquí: el coste. Diez agentes corriendo de forma continua contra un modelo capaz no es gratis, y la factura crece silenciosamente mientras duermes. Tratar el gasto como un filtro más, con presupuestos por sesión y un tope, es la diferencia entre un experimento y una sorpresa.
Si acierto con este peldaño, el tiempo humano se mueve de tareas a decisiones, que es donde realmente pertenece. Todavía no estoy ahí. La mayor parte del tiempo sigo mirando diffs.
7.5 — Construir las bases
El último peldaño antes de un orquestador de verdad es donde las cosas dejan de ser políticas y empiezan a ser código.
En algún momento el dashboard necesita saber algo más que dónde están tus sesiones. Necesita saber qué tareas están en cola y cuáles están en marcha, para que dos agentes no cojan el mismo issue. La versión mínima que llevo bosquejando en la cabeza es una lista compartida de issues abiertos, un flag ligero "claimed", y un hook del lado del agente que lo comprueba antes de coger uno. Apenas cien líneas de código pegamento, y aun así parece que sería la mayor reducción de trabajo duplicado que puedo imaginar.
A partir de ahí las bases se acumulan rápido. Checkpointing de sesiones de larga duración para que un crash no pierda una tarde de trabajo. Credenciales con alcance y corta duración por sesión para que "el agente tiene mis credenciales" deje de ser una frase que te quita el sueño. Una forma de hacer llegar actualizaciones de la especificación a un agente que se arrancó hace veinte minutos.
Nada de eso es todavía un orquestador personalizado. Pero cada una de esas bases es de lo que un orquestador personalizado estaría hecho. Si se acumulan una a una, el Nivel 8 deja de ser un proyecto de fin de semana y pasa a ser la conclusión natural de un montón de pequeñas herramientas pragmáticas. Esta es la dirección en la que mi tooling no deja de empujarme, incluso cuando no estoy construyendo para ello activamente.
Más Allá del Nivel 8: Desarrollo de Software Totalmente Autónomo
El Nivel 8 de Yegge es "construye tu propio orquestador", pero no es el final del camino. Los cinco niveles de Dan Shapiro, del spicy autocomplete a la Dark Factory, describen un destino muy diferente: el Nivel 5, la Dark Factory. Un proceso de software que toma especificaciones como entrada y entrega software como salida, sin que ningún humano escriba ni revise código.
Ya no es hipotético. Simon Willison ha documentado cómo el equipo de tres personas de StrongDM lleva operando así desde mediados de 2025, entregando un codebase de unas 32.000 líneas de Rust, Go y TypeScript bajo la regla de que ningún humano escribe ni revisa el código. Las preguntas que esto plantea, sobre la calidad de las especificaciones, la barrera de información entre quien construye y quien evalúa, y quién rinde cuentas por un codebase que nadie ha leído, merecen un artículo propio.
Por ahora me conformo con decir que no estoy ahí, y no estoy seguro de querer estarlo. La subida que estoy describiendo se queda bastante más acá.
Conclusión
Marcos como el de Yegge son útiles porque nos permiten hablar de dónde estamos y a dónde intentamos llegar. Pero una escalera con un peldaño que falta no es una escalera. Es una caída. Y la caída entre "diez agentes gestionados a mano" y "construye tu propio orquestador" se ha tragado muchos flujos prometedores de desarrollo asistido por IA.
La subida entre ambos no es glamurosa. Es visibilidad, distribución, asincronía, filtrado y pequeñas bases. Cinco peldaños discretos que juntos hacen el Nivel 8 factible y, mucho más importante, hacen el Nivel 7 sobrevivible.
Hay además una segunda pregunta escondida bajo toda esta subida: no cuánto asciendes, sino en torno a qué se construyen las herramientas con las que subes — el proyecto, el agente o tú. Es buena parte de por qué el orquestador acaba siendo tuyo, para que lo construyas.
Si estás en algún punto de esta subida, me gustaría saber dónde. Estoy recogiendo feedback e ideas en las discusiones de ai-beacon mientras trabajo en las herramientas, así que ese es el mejor sitio para comparar notas. Cuantas más compartamos, mejor será la próxima versión de la escala.




