
Building a GitHub Dependents Scraper with Quarkus and Picocli
Introduction
During the past few months, my team and I have been working very hard to release Eclipse JKube. JKube is the successor of the deprecated Fabric8 Maven Plugin, and as such, our main goal right now is to migrate the current user-base to the new project. You can learn more about JKube and how to get started in this other post.
GitHub provides some fancy stats and metrics, including information about the project's dependency graph. This information is really valuable since we get to know which projects (within GitHub) depend on ours. So for our user-base migration use case, this information is spot on. Unfortunately, the GitHub developers API offers information about dependencies, but not about dependents.
In this blog post, I will show you how to create a simple web scraper using Picocli and Quarkus to build a native binary that will scrape dependents for any GitHub project.
Note
Make sure you comply with GitHub Scraping and API Usage Restrictions before using this tool.
Application bootstrap
The first step is to bootstrap the project, we can use the handy code.quarkus.io web interface to generate our project. In this case, we only need Picocli experimental dependency. We'll also need to add the jsoup dependency to our pom.xml.
Since the application will be scraping the GitHub website which uses SSL, we need to enable
the https URL protocol for the GraalVM build. Quarkus Maven Plugin provides a very simple
configuration that allows us to include build arguments for GraalVM to use.
<!-- ... -->
<build>
<plugins>
<plugin>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<executions>
<execution>
<id>package</id>
<goals>
<goal>native-image</goal>
</goals>
<configuration>
<dockerBuild>${dockerBuild}</dockerBuild>
<additionalBuildArgs>
<additionalBuildArg>-H:EnableURLProtocols=https</additionalBuildArg>
<additionalBuildArg>-H:EnableURLProtocols=http</additionalBuildArg>
</additionalBuildArgs>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<!-- ... -->Quarkus Command line application
Next up, we will make our application command-line friendly by using Picocli. There are a few guides online that will help us achieve this, and even a full section in the quarkus-cheat-sheet.
Application Main Class
Our application is really simple and only has an entry-point, so to make things easier, we'll annotate the
application's main class with @CommandLine.Command.
This is the resulting code:
@CommandLine.Command(name = "github-dependents")
public class Application implements Runnable {
private final ScraperService scraperService;
@CommandLine.Parameters(index = "0", paramLabel = "URL", arity = "1",
description = "GitHub URL to the projects dependents list")
String dependentsUrl;
@Inject
public Application(ScraperService scraperService) {
this.scraperService = scraperService;
}
@Override
public void run() {
try {
new URL(dependentsUrl);
scraperService.scrape(dependentsUrl);
} catch(MalformedURLException ex) {
System.err.printf("URL %s is invalid, please provide a valid URL.%n", dependentsUrl);
CommandLine.usage(this, System.out);
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace();
}
}
}Since I want to make this application usable for any GitHub project, I need input from the user specifying which
page they want to scrape. For this purpose, I'll annotate a dependentsUrl field
with @CommandLine.Parameters. Please note how Picocli is very user-friendly and provides a set of
parameters that will be used to generate the CLI help command.
We'll use standard Java CDI @Inject annotation provided by Quarkus to inject the service class that
will be used to perform the scraping.
Scraper Service
This class contains the actual logic that will scrape the GitHub dependents page. The program will recurse through the different pages and return a JSON representation of each dependent including organization, name, URL, stars, and forks.
The service also performs some validations for the user inputs (valid URL, URL belongs to a GitHub dependents
page, etc.) and has some logic to retry in case GitHub returns a 429 - Too Many Requests HTTP
status code.
Running the application
JVM
To run the application using a Java Virtual Machine, first, we need to compile and package the application:
mvn clean packageOnce we've packaged the application we can run it with a target repository of our choice:
java -jar target/github-dependents-scraper-uber.jar "https://github.com/eclipse-jkube/jkube/network/dependents?package_id=UGFja2FnZS0xMDY0ODYxMDkz"Native binary
To run the application using a native binary, first, we need to compile, package and build the native image for the application:
mvn clean package -PnativeOnce the binary file is ready we can run it with a target repository of our choice:
./target/github-dependents-scraper-uber "https://github.com/eclipse-jkube/jkube/network/dependents?package_id=UGFja2FnZS0xMDY0ODYxMDkz"The following GIF shows a quick demo of the application running;
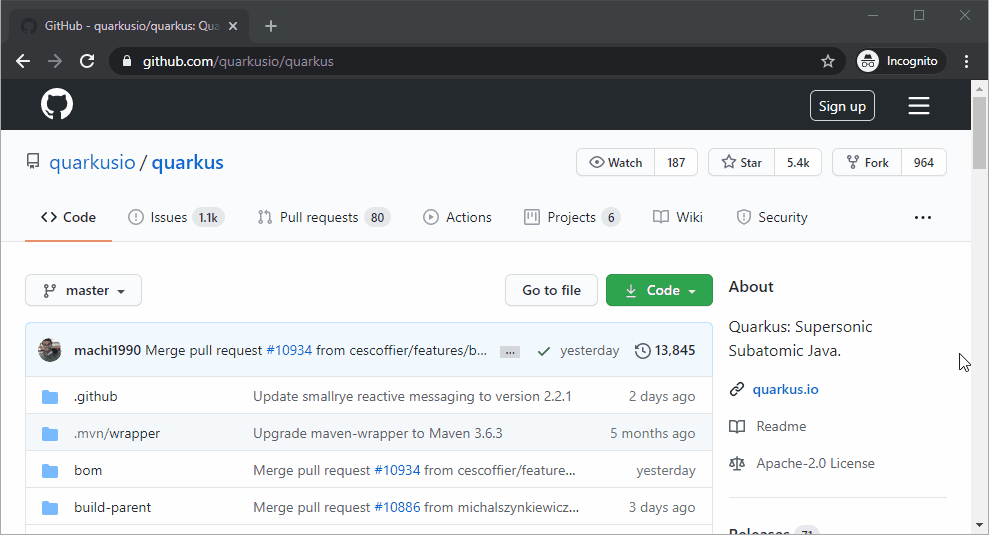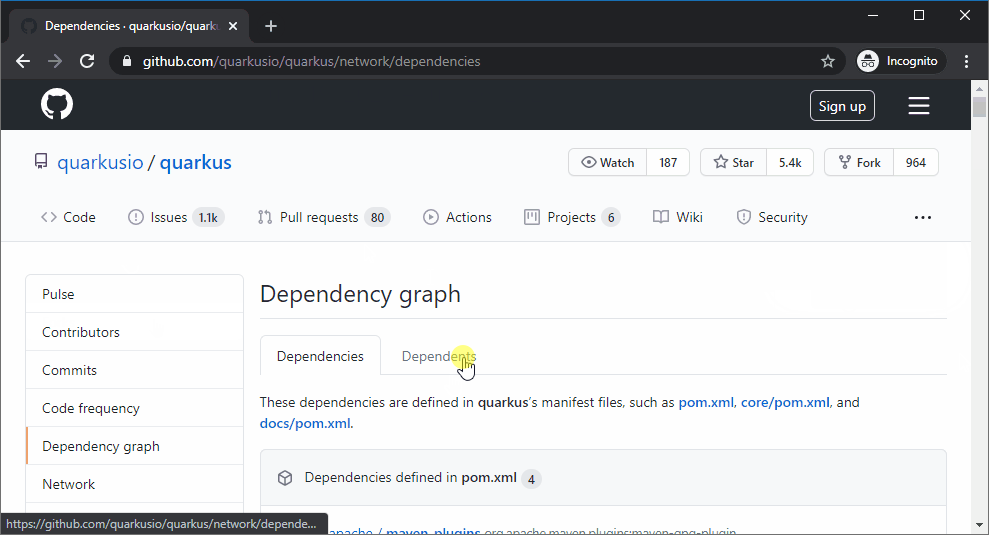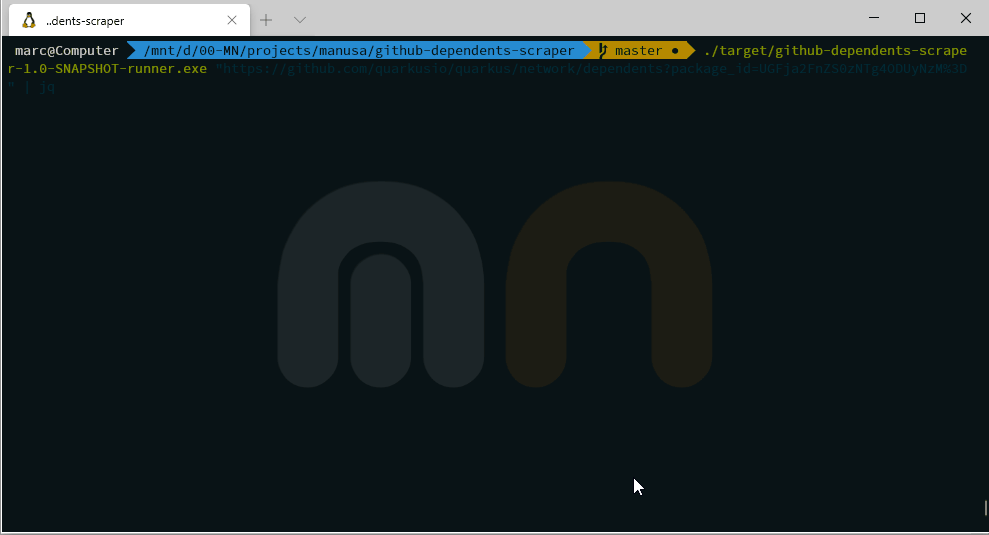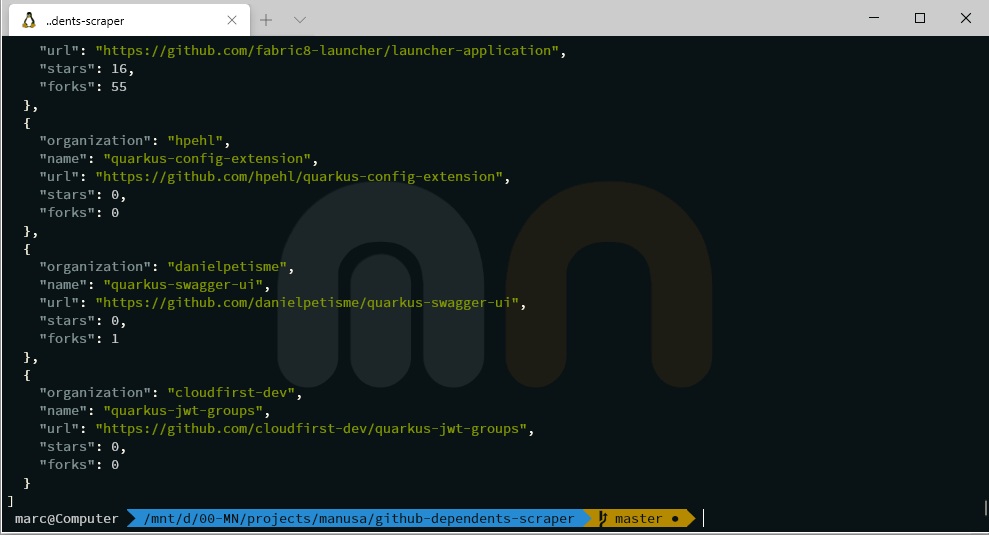
Conclusion
In this article, you've seen how easy it is to create a simple but very useful command-line tool using Quarkus and Picocli, and how to create a native binary with no pain using Quarkus features.
You can check the full source code for this post in the github-dependents-scraper GitHub repository.




